Blog
Answers about Puppet
DevOps, Automation
Universe and Everything
Need Puppet help?
Contact Alessandro Franceschi / example42
for direct expert help on Puppet.
If solution is quick, it’s free. No obligations.
Puppet Tip 116 - Puppet Control-Repo Workflow
When starting with Puppet you usually first create your Puppet GIT control-repository, a single place from where you can rebuild your whole Infrastructure with Puppet.
Within this Puppet control repository you separate upstream library modules (forge modules) from your own code.
Upstream libraries are added to Puppetfile (preferably specifying the version of each module).
It is up to you, whether you just copy and adopt our Open Source Control-Repository or if you prefer to start with an empty repository.
Each branch in the Puppet control repository will be deployed as a Puppet environment.
In both cases you want to carefully consider your workflow on how to get changes into your code base.
Some people consider Puppet environments as platform stages.
But this causes some issues. What if you manage the infrastructure for the application development stage with Puppet using development branch?
Are you totally sure that none of your commits will somehow break the development infrastructure?
How do you bring single feature changes from development to production (maybe via testing branch)?
But you can do different and more easy in the beginning.
The most simple option is to only use the production environment branch and add all changes via feature branches and merge requests.
When working in an ITIL based change management environment this simple approach does not adapt to change management requirements which only allows code changes being tested on dedicated systems prior being deployed to production systems.
This is where one should consider adopting the GIT Flow concept.
This blog post explains the simple, stage branches and the git flow based change workflow for a Puppet control-repository.
Simple workflow
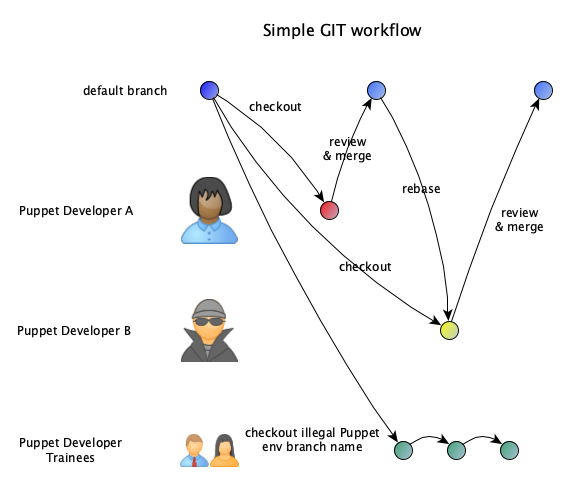
Within the simple workflow you are working with a single long living branch which we usually call production.
We prefer to set this branch to “protected” to prevent any direct changes. All changes must be delivered using feature branches which will be merged into production branch.
When working with multiple people in different feature branches, everyone must rebase their branches on a regular basis, at least prior creating the merge request.
This is similar to many upstream development procedures of most Puppet library module code.
Pro:
- easy to learn
Con:
- changes on Puppet code affect all systems at once
An example:
prod prod
| |
feature
You will start by creating your own feature branch:
git checkout -b <feature_branch>
At customers we usually recommend to build the name of the branch based upon user or team name. e.g. git checkout -b alfke_new_db_role.
Additionally we recommend to work with rebase on feature branches instead of merge. Rebasing will take care that your feature branch changes are placed after any other production changes.
If you see changes on production branch you need to rebase: git rebase origin/production
Any feature branch should result in a merge request. Every merge request should consist of a single commit only. The best option is to use git commit --amend on any additional change or to squash all commits once your feature is ready to get deployed.
Transfer Branch
But how do you proceed when there is a requirement for following changes in stages independently?
How do you follow your implementation documentation standards?
Some infrastructures require network separation between development and production systems.
This also affects Puppet Code and GIT Server, as you will have multiple installations.
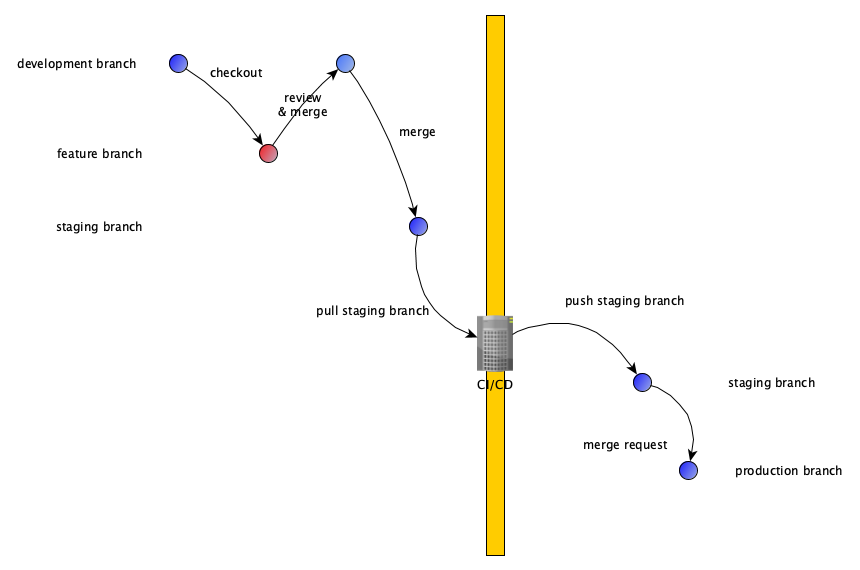
In this case we recommend to only work on the development side using feature branches. A special transfer branch gets updates and has a CI system with access to both networks, so it can pull code from the development git transfer branch and pushes changes into the production git transfer branch.
On the production git a merge request is generated to merge changes from transfer into production.
On development git you only have development, transfer and feature branches.
On production git you have transfer and production branch.
Pro:
- security concerns like network separation are taken care on
Con:
- needs automatic merging and staging, no manual merges up to production merge request.
GIT Flow
But how to proceed, if you want to have Puppet code available for each of your infrastructure stages?
In this case you have to create several long living branches like development, testing and then production. You can use any string lower case letters and numbers and underscore as environment name. Maybe you prefer other naming like dev, qa, int, pre_prod, prod.
But using multiple branches makes it harder to deploy single changes independently. What will happen upon merge if you have two changes within the development branch and only the second one may be deployed to the next branch?
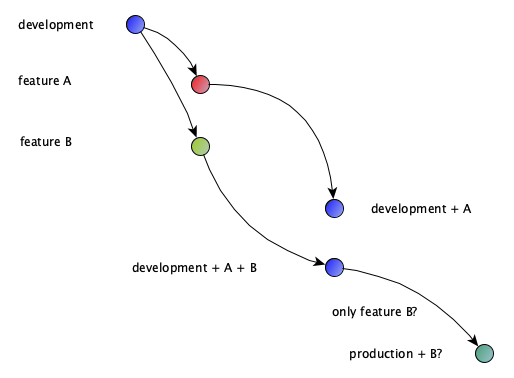
One must reconsider on how you look at your branches within your GIT repositories: Instead of just seeing one single code base within a GIT repository you should see several loosely coupled streams of code placed into branches on a single GIT repository.
Each of these code stream branches can be developed and improved independently and all development must be done in a stream feature/change branch.
All workflows must be tracked within a ticket. Within this change ticket you follow work and deployment be placing them into subtasks for each stream branch.
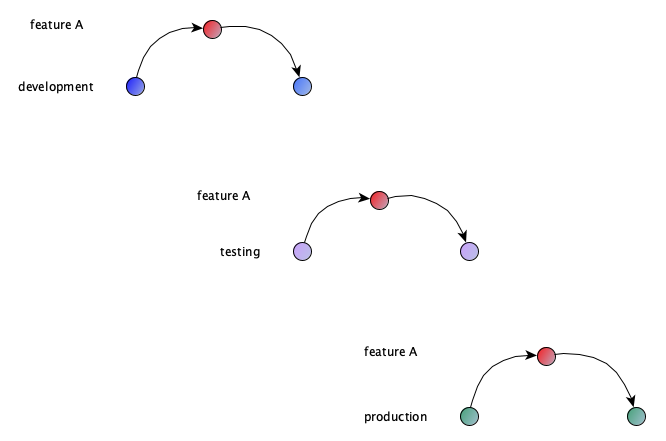
To allow independent changes still being transferred from one branch to another, you must take care that a single merge request consists of a single commit only.
You can achieve this by using git commit --amend or by running git squash.
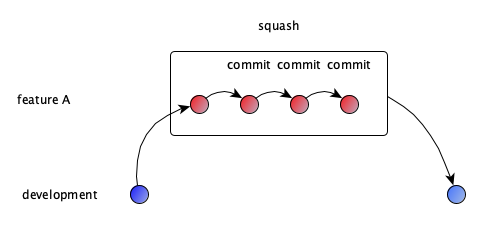
This might look like duplicate work, as you need to apply the same change in multiple places.
But on the other hand, this deployment and staging methods allows you to also deploy hotfixes in production and backporting them to development by using git cherry-pick.
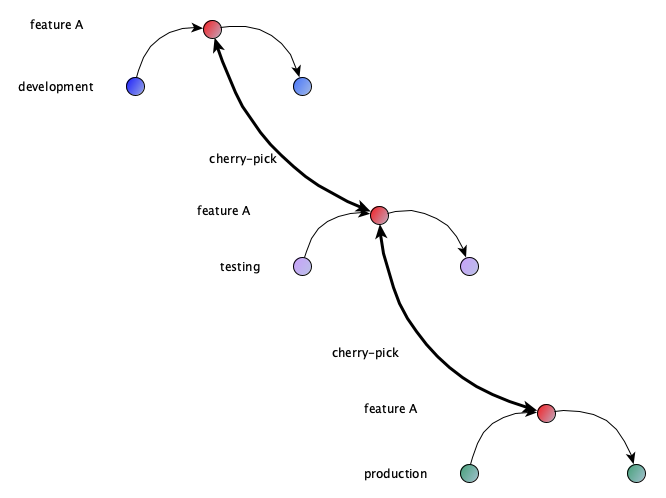
Multiple branches have several additional requirements:
- Rebase and Squashing is a hard must for each merge.
- Cherry-Picking is the way to get a change from one feature branch to another.
- All long living branches must be protected. Changes may only be added via merge requests. No exceptions allowed.
- Normal code staging is done by merging into dev and cherrypicking the change into a merge request to the other branches.
- Hotfixes in testing are developed on testing feature branch, forwarded via cherry-pick to production feature branch and backported (also cherry-pick) into development feature branch.
- Hotfixes on production branch are developed on production feature branch and are backported via development feature branch and testing feature branch (both cherry-pick).
Pro:
- adopts agile and waterfall concepts
Con:
- needs more GIT knowledge
Recommendations
When to use which solution?
What are characteristics which will make you consider using staging branch or GIT Flow. What are the requirements?
Deploy fast and often? Single platform, no stages? -> Use simple
Deploy fast and often? Platform separation e.g. network isolation? -> Use staging branch
Deployment may stuck for weeks in a specific stage? Deployments are rare and slowly? ITIL based change management and change approval process? -> Use GIT Flow
Switching to GIT Flow allows more flexible handling of complex change approval requirements but needs more understanding on GIT squash, rebase and cherry-pick and how to deal with merge conflicts.
Get yourself a proper GIT Server (appliance). Automate everything. Happy hacking,
Martin Alfke